中日汉字差异对比
| 日 | 中 | 备注 |
|---|---|---|
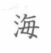 |
海 | 日文中每字中“母”的两点是连起来的,例如:海、每等,但母字的写法中日汉字是一样的 |
 |
每 | |
 |
母 |
| 日 | 中 | 备注 |
|---|---|---|
|
海 | 日文中每字中“母”的两点是连起来的,例如:海、每等,但母字的写法中日汉字是一样的 |
|
每 | |
|
母 |
一类形容词(形容词/い形容词),以「い」结尾
高い(たかい)、いい、大きい(おおきい)

二类形容词(形容动词/な形容词),词干+「だ」
静かな(しずかな)、元気な(げんきな)、、綺麗な(きれいな)

1、た形,表过去式
い形容词:去掉词尾的い+かった(弱い→弱かった)
な形容词:词干+だった
2、ない形,表否定式
い形容词:词尾的い→く+ない(悪い→悪くない)
な形容词:词干+ではない
3、过去否定式
い形容词:去掉ない形的词尾い+かった(若くない→若くなかった)
な形容词:词干+ではなかった
4、て形,用于多个形容词同时进行修饰的场景
い形容词:词尾的い→く+て(高い→高くて)
な形容词:词干+で
本周遇到一个问题是一开始一个.ts文件的后缀不小心写成了.TS ,反反复复pull push了好几次,每次都要重新修改回.ts 。后来才知道只是更改文件名的大小写在github看起来是没有修改的,必须要先把文件名字改成别的,push之后再改回原来的才行。
git branch
git branch | grep ‘dev*’ | xargs git branch -d
| :管道命令,用于将一串命令串联起来。前面命令的输出可以作为后面命令的输入。
grep:搜索过滤命令。使用正则表达式搜索文本,并把匹配的行打印出来。
xargs:参数传递命令。用于将标准输入作为命令的参数传给下一个命令。
本周遇到一个问题是一开始一个.ts文件的后缀不小心写成了.TS ,反反复复pull push了好几次,每次都要重新修改回.ts 。后来才知道只是更改文件名的大小写在github看起来是没有修改的,必须要先把文件名字改成别的,push之后再改回原来的才行。
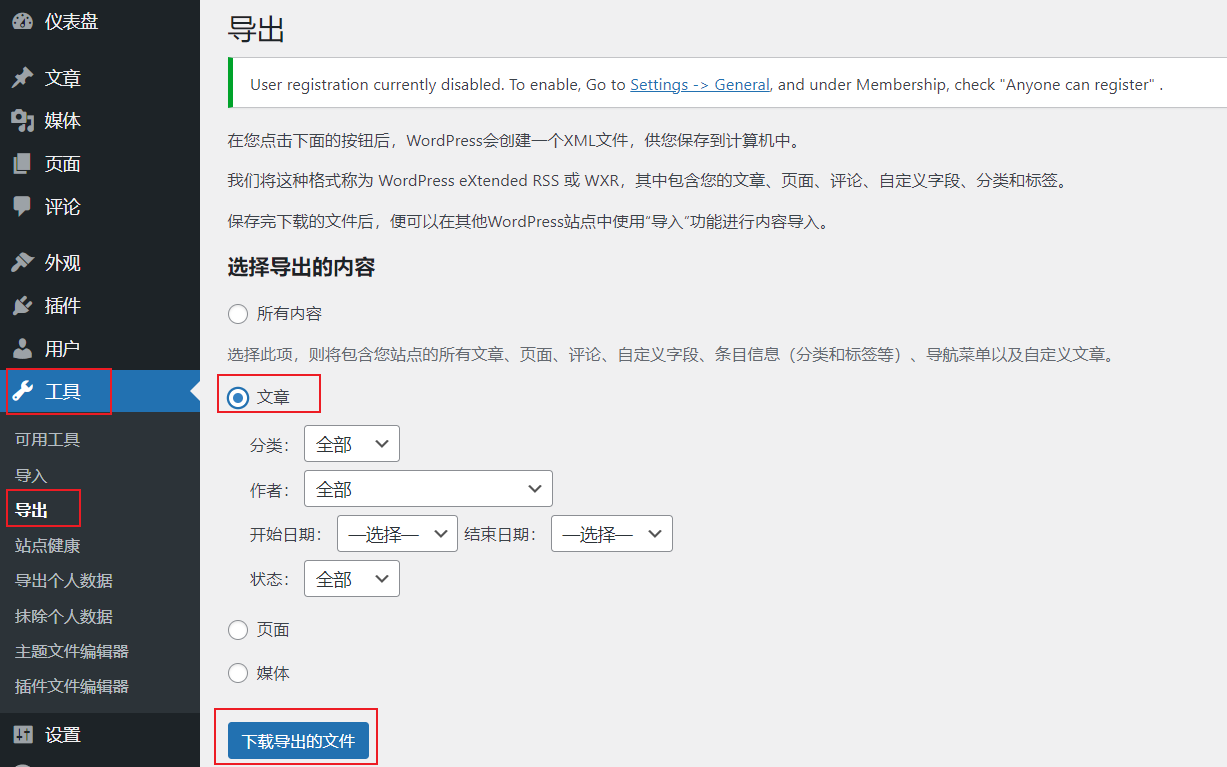
从wordpress admin 后台 - 工具 - 到处 -文章,下载导出的文件,注意,一定要选文章
创建xxx.py文件,代码如下
# -*- coding: utf-8 -*-
from lxml import etree
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8')
def getText(element):
return element.text
def getCategory(elementList):
for element in elementList:
if element.attrib['domain'] == 'category':
return element.text
def parse(wordpress_file):
tree = etree.parse(wordpress_file)
root = tree.getroot()
for post in root.iter('item'):
# Title
title = getText(post.find('title'))
output = open(output_path + '\\%s.md' %
title.replace(' ', '-').replace('/', '-'), 'w+', encoding='utf8')
output.write("Title: %s" % title+"\n")
outputT.write("Title: %s" % title+"\n")
# Date
date = post.find('{%s}post_date' % wp_namespace).text
output.write("Date: %s" % date+"\n")
outputT.write("Date: %s" % date+"\n")
# Tags
tags = post.findall('category')
tagsList = ', '.join(list(map(getText, tags)))
output.write("Tags: %s" % tagsList+"\n")
outputT.write("Tags: %s" % tagsList+"\n")
# Category
category = getCategory(tags)
output.write("Category: %s" % category+"\n")
outputT.write("Category: %s" % category+"\n")
content = post.find(
'{%s}encoded' % content_namespace ).text.replace('\xa0', '')
output.write("\n" + content+"\n")
outputT.write("\n" + content+"\n")
output.close()
###############################################################################
if __name__ == "__main__":
# 备份文件绝对路径
input_path = "C:\\Users\\SummerLiu\\Downloads\\WordPress.2022-10-08 (1).xml"
# 目标Markdown文件夹的绝对路径
output_path = "C:\\Users\\SummerLiu\\Downloads\\wordpress\\md"
# namespace content
content_namespace = 'http://purl.org/rss/1.0/modules/content/'
# namespace wp
wp_namespace = 'http://wordpress.org/export/1.2/'
outputT = open(output_path + '\\total.md', 'w+', encoding='utf8')
parse(input_path)
outputT.close()
其中,input_path 为 备份文件的绝对路径,output_path为目标Markdown文件夹的绝对路径(文件夹提前建好,否则会报错文件夹不存在)
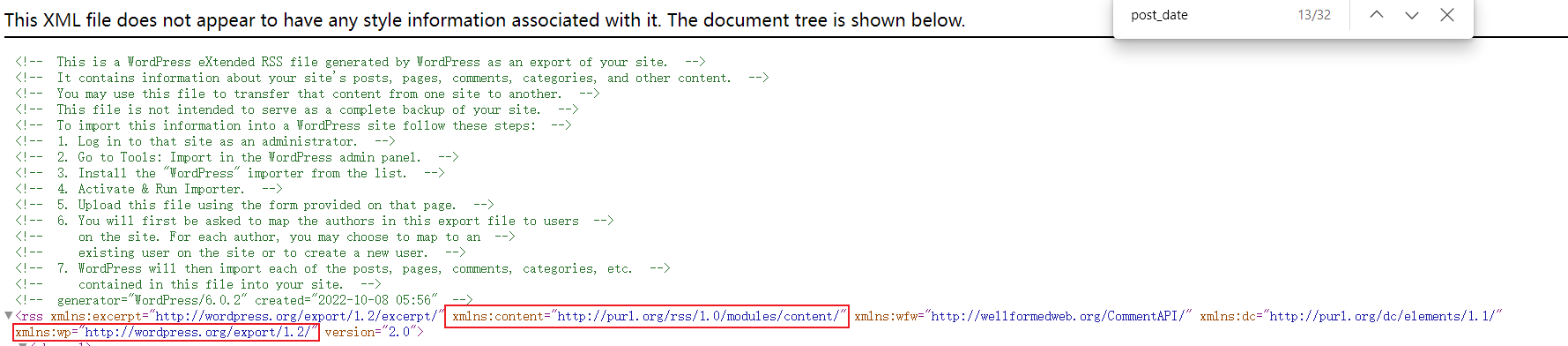
用浏览器打开Wordpress备份文件(后缀为.xml),看到下面红框框起来的两个网址,将蓝色网址粘贴到 content_namespace 和 wp_namespace 处进行替换,content_namespace对应xmlns:content后的网址,wp_namespace 对应xmlns:wp后的网址。

运行下面的命令,安装依赖库 lxml
pip install lxml
安装成功后,运行xxx.py文件
python "c:\Users\Downloads\xxx.py"
打开对应的文件夹,即可收获wordpress文章的Markdown文件
一个用于把各个文件夹中的多个pdf合并为一个pdf,并以文件夹的名字为PDF名的小脚本。
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:\\Users\\SummerLiu\\Downloads\\Summer'
pdf_lst = [f for f in os.listdir(target_path)]
print('pdf_lst: ',pdf_lst)
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
print('pdf_lst1: ',pdf_lst)
for dir in pdf_lst:
print('dir: ',dir)
print('os.listdir(dir): ',os.listdir(dir))
file_merger = PdfFileMerger()
for pdf in os.listdir(dir):
pdf_file = os.path.join(dir, pdf)
file_merger.append(pdf_file)
file_merger.write(dir+".pdf")
style={{ whiteSpace: 'pre-line', textOverflow: 'ellipsis' }}
https://pro.ant.design/zh-CN/docs/debug
在我们的开发中,由于对底层的不理解或者兼容性的问题,很有可能会出现白屏或者 Out Of Memory 的问题,也有一些问题没有任何可以 debug 着手的方式。这时候就要用到一些 debug 的方案。
二分法是 debug 中最常用也是最好用的方式,非常适用于我的代码昨天还是好的和各类 Out Of Memory 报错。我们可以程序逻辑一点点注释掉,不断地进行排错,完全能把问题可能出现的范围缩小,然后找出罪魁祸首。再用常规手段调试。
node 中 Out Of Memory 最常用的方式就是删除一半依赖,然后进行重试来不断缩小范围,直到找个问题所在。二分调试大法每次遇到棘手的 bug,基本上都能解决,程序员必备技能,无关语言。
处理 bug 的过程,最难的不是怎么解决问题,而是如何定位代码的 bug,如果实在是一筹莫展,尤其是算法类的问题。我们可以通过小黄鸭法来进行 debug。我们可以找任何物体也可以是同事讲一遍或者讨论一遍,当然上网发帖也是好方式。
这个方法成本最高,适用于可以乱七八糟的代码,尤其是陈年代码,如果实在搞不懂修不了 bug,可以加好测试用例重新写一遍。毕竟很多的 bug 其实都是错别字。